Créer un fichier CVS
Le traitement des inscriptions en masse se fait en téléchargeant des fichiers CSV. Ces fichiers sont des fichiers de texte brut qui peuvent contenir plusieurs inscriptions à la fois et sont extraits de votre système principal.
La première étape consiste à créer correctement le fichier.
Utilisation d'un éditeur de CSV
Bien qu'Excel soit un bon outil pour visualiser les CSV, nous ne le recommandons pas pour les modifier. Utilisez plutôt Notepad++ ou tout autre éditeur de texte. Voici quelques risques dont vous devez être conscient lorsque vous modifiez un CSV dans Excel. Excel interprétera le contenu, ce qui peut entraîner des modifications :
- Les zéros non significatifs disparaissent dans les champs reconnus comme des champs numériques
- Des entrées comme 3-9 peuvent devenir Mai-9
- Le seul format de date accepté, JJ/MM/AAAA, peut être modifié (par exemple, à JJ/MM/AA)
- Le séparateur décimal peut être différent de celui utilisé dans HD4DP, un point-virgule permettra un téléchargement correct
- Lorsque vous enregistrez un fichier au format .csv, Excel utilise le séparateur de champs par défaut. HD4DP n'accepte que les CSV avec un point-virgule comme séparateur. Ce paramètre par défaut peut être adapté dans les propriétés de votre ordinateur.
- L'encodage CSV doit être en UTF-8
Mise en place du document
Chaque colonne du fichier CSV doit être reconnue comme un champ du registre par l'application HD4DP. Par conséquent, chaque colonne du fichier doit être identique au nom technique du champ du registre.
Conseil : Le téléchargement des données saisies (manuellement) à partir de HD4DP vous guidera dans le formatage d'un fichier CSV et pourra vous aider lors de l'élaboration de l'extraction CSV à partir des systèmes primaires.
Les spécifications pour chaque registre et ses champs sont définies et documentées comme mentionné sur https://www.healthdata.be/dcd.
Chaque champ du formulaire peut être complété par une valeur dans un fichier CSV.
Un exemple de champ est "Date du dernier suivi", illustré dans la capture d'écran ci-dessous.
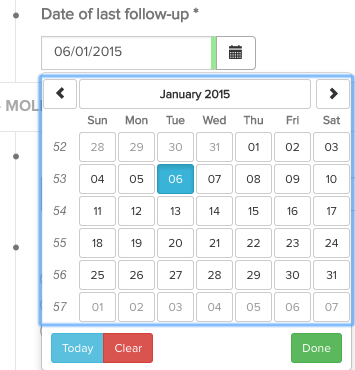
Ce champ est du type "date" et est obligatoire (*). Dans la documentation technique de cette collecte de données, il est indiqué comme suit :

Pour inclure ce champ dans un fichier CSV, il suffit de créer une colonne portant le nom de "date_du_dernier_suivi" et de la remplir avec les données appropriées, c'est-à-dire une date au format jj/mm/aaaa.
Les champs peuvent être obligatoires, en lecture seule et calculés (calcul automatique). Les champs peuvent également avoir une valeur par défaut.
Ces informations sont présentes dans la description technique détaillée de chaque collecte de données.
Conditions générales
- Le séparateur de colonne est le point-virgule ( ;)
- Le séparateur décimal pour les nombres est la virgule (,)
- Le format de la date est jj/mm/aaaa
Types de contenu de base
Selon le type de champ, une représentation différente des données est attendue. Le tableau ci-dessous décrit les différents types de base et les règles à suivre pour fournir le contenu de ces types.
| Content type | Expected format/content |
| boolean | TRUE, FALSE |
| date | dd/mm/yyyy |
| choice | code from choice list |
| list | option1_label|option2_label|etc. |
| multiline | free text |
| number | number (decimal separator = ,) |
| patientID | SSIN number. If the person does not have a SSIN, leave this field blank. |
| questionnaire | code from questionnaire answer list |
| text | ● free text ● if a binding reference list is used: a code from the reference list ● if a non-binding reference list is used: a code from the reference list or free text |
| attachment | ● expected format/content: Name of the file that must be attached (e.g. protocol.txt). ● expected extension: .txt ● file must be stored in the same folder as the folder that is used for the CSV-upload |
Types de contenu avancés
Outre ces types simples, des structures de données plus complexes peuvent être utilisées, comme le montre le tableau ci-dessous. Chacun de ces types est expliqué plus en détail sous le tableau.
| Content type | CSV column name | Expected format |
| fields within fieldset | fieldset_label|field_label | depending on the field type |
| list (1 field) | list_label|field | value1|value2|etc |
| list (block of fields) | list_label|0|field1 list_label|0|field2 list_label|1|field1 list_label|1|field2 etc. | depending on the field type |
| nested fields below choice or multichoice | choice_label|nested_item | depending on the field type |
Groupe de champs
Un groupe de champs est une collection de champs, comme le montre l'image ci-dessous :
Anthropométrie est le titre du groupe de champs, et ce groupe de champs contient deux champs, le poids et la taille. Les groupes de champs n'ont pas de numéro cf. image ci-dessous - Anthropométrie.

Les sections n'ont pas d'impact sur le fichier CSV, alors que les groupes de champs en ont un. Le titre du groupe de champs doit être inclus dans la colonne du nom du champ, comme suit : fieldset_label|field_label.
Par exemple, pour les deux groupes de champs Anthropométrie - poids et taille - ci-dessous, les en-têtes de colonne CSV corrects sont : anthropométrie|poids et anthropométrie|taille.
Listes
Une liste est également une collection de champs, comme un groupe de champs, mais avec la propriété supplémentaire que la collection de champs peut être répétée.
Un exemple est montré dans l'image ci-dessous : "Jours de naissance des enfants biologiques de ce patient" est une liste. Un élément de liste est constitué de deux champs, "Mois de naissance de l'enfant" et "Année de naissance de l'enfant". Pour chaque enfant, un élément de liste peut être ajouté.
Les noms des colonnes CSV se composent de l'étiquette de l'en-tête de la liste et de l'étiquette du champ (comme pour les groupes de champs), ainsi que d'un compteur permettant de distinguer les différents éléments de la liste. Les noms de colonnes CSV corrects pour les deux éléments de la liste ci-dessous sont :
- birthdays_of_the_biological_children_for_this_patient|00|child_birth_month
- birthdays_of_the_biological_children_for_this_patient|00|child_birth_month
- birthdays_of_the_biological_children_for_this_patient|01|child_birth_month
- birthdays_of_the_biological_children_for_this_patient|01|child_birth_year
Veuillez noter que pour chaque ligne, les chiffres doivent s'acroitrent, en partant de 0 (|00|,|01|, … est correct, |01|, |03|, … ne l'est pas). Vous ne pouvez pas avoir des valeurs vides pour |00| et des valeurs pleines pour un nombre supérieur.
Veuillez noter que la numérotation exige un format stable, ce qui signifie que le nombre de caractères utilisés par le numéro doit être constant. Vous ne pouvez pas avoir un enregistrement utilisant |00| et un autre utilisant |0|. En général, nous conseillons d'utiliser une longueur de chaîne de 2 chiffres.

Pour les listes composées d'un seul champ, une mise en œuvre simplifiée est possible. L'en-tête de colonne CSV ne comprend que l'étiquette d'en-tête de la liste et plusieurs valeurs sont fournies dans une seule colonne, séparées par un tube (|).
Par exemple, pour la liste de l'image ci-dessous, l'en-tête de la colonne CSV est diagnostic_orphacode et le contenu de la colonne est 562|702. C'est l'exemple d'un champ texte avec une liste de référence : fournir les codes de la liste de référence est suffisant.

Champs imbriqués
Les champs imbriqués sont des champs qui ne deviennent disponibles que lorsque des options spécifiques sont sélectionnées dans le formulaire. En voici un exemple : le champ "Spécifier" ne devient disponible que si la case "Autre" est cochée. Ces champs ont également un en-tête de colonne CSV combiné, composé de l'étiquette de la liste de choix et de l'étiquette du champ. Dans l'exemple ci-dessous, l'en-tête de colonne CSV correct est donc base_of_diagnosis|specify.

Pièces jointes
Lorsqu'un CSV est préparé et placé dans le dossier fourni, il peut contenir des références à des pièces jointes pour les collectes de données qui le permettent spécifiquement.
Ces références sont des chemins relatifs vers l'emplacement du fichier. Si une telle référence est présente dans le fichier CSV, le contenu de la pièce jointe est téléchargé et lié à l'enregistrement créé. La pièce jointe est alors disponible dans le client HD4DP ainsi que dans le client HD4RES lorsque l'enregistrement est soumis.
La taille maximale des fichiers joints est de 6 MB
Si une collecte de données vous permet d'envoyer des pièces jointes, vous devriez avoir le nom de la colonne à utiliser dans le CSV. Si ce n'est pas le cas, vous devriez pouvoir le trouver à l'adresse suivante https://www.healthdata.be/dcd/#/collections ou vous pouvez contacter Support.Healthdata@sciensano.be.
Ajoutez le nom de la colonne à l'en-tête du CSV et ajoutez les noms de fichiers comme valeurs dans la colonne.
Exemple : "image.png"
Placez le fichier CSV dans le bon dossier fourni (sous-dossier organisation, puis sous-dossier enregistrement), ainsi qu'un fichier "image.png" de votre choix. L'application récupère le fichier CSV et crée un nouvel enregistrement.
Ouvrez l'enregistrement et vérifiez que la pièce jointe a été correctement téléchargée.